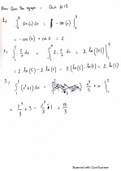Distributed Databases
Introduction to Distributed Databases
A distributed database is a type of database that stores data across multiple
physical locations. These databases provide advantages in scalability, fault
tolerance, and high availability, making them essential for large-scale applications
and services.
In a distributed database system:
The data is stored on multiple machines (nodes).
The system provides transparent access to users, allowing data to be
retrieved or written as if it were stored on a single machine.
Characteristics of Distributed Databases
1. Location Transparency: The users and applications interacting with the
database do not need to know where the data is physically stored. The
system abstracts the location of data.
2. Scalability: Distributed databases can scale horizontally by adding new
nodes or vertically by increasing the resources of existing nodes.
3. Fault Tolerance: If one node or server fails, other nodes continue to
function, ensuring high availability and data resilience.
4. Concurrency Control: Multiple users can access and manipulate the
database at the same time, without conflicts.
5. Transparency: Distributed databases provide transparency in various ways,
such as:
o Replication Transparency: Users are unaware of data replication
across nodes.
o Fragmentation Transparency: Users are unaware of how data is
fragmented across nodes.
, Types of Distributed Databases
1. Homogeneous Distributed Databases:
o All nodes use the same database management system (DBMS).
o The data schema is uniform across all nodes.
2. Heterogeneous Distributed Databases:
o Different nodes may use different DBMS or database models (e.g.,
relational, NoSQL).
o The schema might differ between nodes, requiring data translation
mechanisms.
3. Architectures:
o Peer-to-Peer: Every node is equally capable of both data storage and
processing. There is no centralized control.
o Client-Server: Nodes are divided into clients (requesters of data) and
servers (providers of data). Clients make requests, and servers
respond with the requested data.
Distributed Database Models
1. Shared-Memory Model:
o All nodes share the same memory. It is generally used in smaller
systems where all nodes can access the same physical memory, but it
is less scalable for large systems.
2. Shared-Disk Model:
o All nodes have access to the same disk, though each node may have
its own memory. Common in systems requiring high throughput.
3. Shared-Nothing Model:
o Each node has its own storage and memory, and nodes communicate
over the network. This model is the most scalable and fault-tolerant,
making it ideal for large distributed systems.
Data Distribution Techniques
1. Horizontal Partitioning (Sharding):
Introduction to Distributed Databases
A distributed database is a type of database that stores data across multiple
physical locations. These databases provide advantages in scalability, fault
tolerance, and high availability, making them essential for large-scale applications
and services.
In a distributed database system:
The data is stored on multiple machines (nodes).
The system provides transparent access to users, allowing data to be
retrieved or written as if it were stored on a single machine.
Characteristics of Distributed Databases
1. Location Transparency: The users and applications interacting with the
database do not need to know where the data is physically stored. The
system abstracts the location of data.
2. Scalability: Distributed databases can scale horizontally by adding new
nodes or vertically by increasing the resources of existing nodes.
3. Fault Tolerance: If one node or server fails, other nodes continue to
function, ensuring high availability and data resilience.
4. Concurrency Control: Multiple users can access and manipulate the
database at the same time, without conflicts.
5. Transparency: Distributed databases provide transparency in various ways,
such as:
o Replication Transparency: Users are unaware of data replication
across nodes.
o Fragmentation Transparency: Users are unaware of how data is
fragmented across nodes.
, Types of Distributed Databases
1. Homogeneous Distributed Databases:
o All nodes use the same database management system (DBMS).
o The data schema is uniform across all nodes.
2. Heterogeneous Distributed Databases:
o Different nodes may use different DBMS or database models (e.g.,
relational, NoSQL).
o The schema might differ between nodes, requiring data translation
mechanisms.
3. Architectures:
o Peer-to-Peer: Every node is equally capable of both data storage and
processing. There is no centralized control.
o Client-Server: Nodes are divided into clients (requesters of data) and
servers (providers of data). Clients make requests, and servers
respond with the requested data.
Distributed Database Models
1. Shared-Memory Model:
o All nodes share the same memory. It is generally used in smaller
systems where all nodes can access the same physical memory, but it
is less scalable for large systems.
2. Shared-Disk Model:
o All nodes have access to the same disk, though each node may have
its own memory. Common in systems requiring high throughput.
3. Shared-Nothing Model:
o Each node has its own storage and memory, and nodes communicate
over the network. This model is the most scalable and fault-tolerant,
making it ideal for large distributed systems.
Data Distribution Techniques
1. Horizontal Partitioning (Sharding):