College 3
Multipele regressie: meerdere voorspellers
Y1= b0 + bix1 + b2x2 ..
B1 = verwachte waarde wanneer x verhoogd met 1 punt terwijl de andere voorspellers
constant blijven
R2 = alles van de variantie wat we kunnen verklaren
Gestandaardiseerde Beta’s: in z-scores, je kunt kijken welke voorspeller sterker is dan de
andere
Inter-item correlaties: wanneer de correlatie tussenbeide voorspellersrelatief hoog is. Ze
kunnen ook hoog correleren met de afhankelijke variabelen. R2 is kleiner wanneer de
voorspellers hoog gecorreleerd zijn. Wanneer ze niet gecorreleerd zijn heb je meer power,
een beter model en kan je meer voorspellen. Wanneer er niet voldaan is aan de assumpties
wordt dit duidelijker te zien in een goed voorspellend model.
Dichotome variabele: kan verwerkt worden in een regressieanalyse, je kunt nog steeds een
relatie aangeven tussen variabelen. Je kunt nooit een dichotome afhankelijke variabele
hebben, wel een dichotome onafhankelijke variabele.
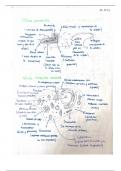
Wanneer je meerdere onafhankelijke variabelen hebt kijk je naar de mahanalobis afstand
voor outliers en naar de cook’s afstand. Bij 1 of 2 variabelen kijkje naar een histogram,
scatterplots en gestandaardiseerde residuen. Bij 3 of meer variabelen kijk je naar de
Mahanalobis of Cook’s afstand.
Assumpties:
Gestandaardiseerde residuen: moeten tussen de -3 en 3 liggen om te kijken naar
outliers. Ze moeten normaal verdeeld zijn, vooral bij een kleine N, anders zijn de p-
waardes niet meer betrouwbaar. Bij meerdere pieken van een histogram test je
misschien meerdere sub samples. Dit is ook het geval wanneer je in het QQ-plot een
s-vormige lijn hebt. Bij skewness naar rechts vindt je hier een U-vormige lijn, bij
skewness naar links een omgekeerde U-vorm.
Lineairiteit: kijken naar het residual plot (zresid versus zpred). Wanneer hier een
krom patroon ontstaat is de data niet optimaal. Ook kijken naar scatterplot. Hierin
kun je een kromme of rechte lijn tekenen en kijken welke R2 de meeste variantie
verklaard. Wel belangrijk om te kijken hoe groot de sample is.
Homoskedasticiteit: voor elke waarde van de vorspeller moet de variatie van de
residuen gelijk zijn. Kijken naar residuenplot, wanneer de residuen hoger worden bij
voorspellende waardes kun je mogelijk de heteroskedasticiteit verklaren met een
andere variabele -> moderatie.
Multicollineaiteit: voorspellers mogen niet hoog met elkaar gecorreleerd zijn.
Waardes van 0.8 en hoger zijn hoog. Ook kijken naar vif en tolerantie. Bij een Vif > 10,
tolerantie <.10 en een correlatie van 0.8 of 0.9 is er een probleem. Wanneer ze hoog
gecorreleerd zijn kun je ze verwijderen (omdat ze correleren kijk je waarschijnlijk
naar hetzelfde) of je kunt ze combineren (total score).
Bouncing beta’s: omdat er een hoge correlatie is tussen twee variabelen wordt 1 van
de beta’s negatief/positief, terwijl je de relatie de andere kant op verwacht.
Multipele regressie: meerdere voorspellers
Y1= b0 + bix1 + b2x2 ..
B1 = verwachte waarde wanneer x verhoogd met 1 punt terwijl de andere voorspellers
constant blijven
R2 = alles van de variantie wat we kunnen verklaren
Gestandaardiseerde Beta’s: in z-scores, je kunt kijken welke voorspeller sterker is dan de
andere
Inter-item correlaties: wanneer de correlatie tussenbeide voorspellersrelatief hoog is. Ze
kunnen ook hoog correleren met de afhankelijke variabelen. R2 is kleiner wanneer de
voorspellers hoog gecorreleerd zijn. Wanneer ze niet gecorreleerd zijn heb je meer power,
een beter model en kan je meer voorspellen. Wanneer er niet voldaan is aan de assumpties
wordt dit duidelijker te zien in een goed voorspellend model.
Dichotome variabele: kan verwerkt worden in een regressieanalyse, je kunt nog steeds een
relatie aangeven tussen variabelen. Je kunt nooit een dichotome afhankelijke variabele
hebben, wel een dichotome onafhankelijke variabele.
Wanneer je meerdere onafhankelijke variabelen hebt kijk je naar de mahanalobis afstand
voor outliers en naar de cook’s afstand. Bij 1 of 2 variabelen kijkje naar een histogram,
scatterplots en gestandaardiseerde residuen. Bij 3 of meer variabelen kijk je naar de
Mahanalobis of Cook’s afstand.
Assumpties:
Gestandaardiseerde residuen: moeten tussen de -3 en 3 liggen om te kijken naar
outliers. Ze moeten normaal verdeeld zijn, vooral bij een kleine N, anders zijn de p-
waardes niet meer betrouwbaar. Bij meerdere pieken van een histogram test je
misschien meerdere sub samples. Dit is ook het geval wanneer je in het QQ-plot een
s-vormige lijn hebt. Bij skewness naar rechts vindt je hier een U-vormige lijn, bij
skewness naar links een omgekeerde U-vorm.
Lineairiteit: kijken naar het residual plot (zresid versus zpred). Wanneer hier een
krom patroon ontstaat is de data niet optimaal. Ook kijken naar scatterplot. Hierin
kun je een kromme of rechte lijn tekenen en kijken welke R2 de meeste variantie
verklaard. Wel belangrijk om te kijken hoe groot de sample is.
Homoskedasticiteit: voor elke waarde van de vorspeller moet de variatie van de
residuen gelijk zijn. Kijken naar residuenplot, wanneer de residuen hoger worden bij
voorspellende waardes kun je mogelijk de heteroskedasticiteit verklaren met een
andere variabele -> moderatie.
Multicollineaiteit: voorspellers mogen niet hoog met elkaar gecorreleerd zijn.
Waardes van 0.8 en hoger zijn hoog. Ook kijken naar vif en tolerantie. Bij een Vif > 10,
tolerantie <.10 en een correlatie van 0.8 of 0.9 is er een probleem. Wanneer ze hoog
gecorreleerd zijn kun je ze verwijderen (omdat ze correleren kijk je waarschijnlijk
naar hetzelfde) of je kunt ze combineren (total score).
Bouncing beta’s: omdat er een hoge correlatie is tussen twee variabelen wordt 1 van
de beta’s negatief/positief, terwijl je de relatie de andere kant op verwacht.