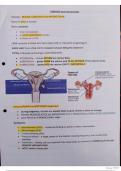
Samenvatting
Summary IPRes Notes Exam Part 2
- Instelling
- Universiteit Van Amsterdam (UvA)
- Boek
- Beginning Statistics
This is a comprehensive summary for the second exam in IPRes 2019. It contains all the notes from the lectures, slides, and notes from all the assigned readings, organized and well explained.
[Meer zien]